冒泡排序
重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。顾名思义,让大(小)的数值逐渐冒出来(浮上来)。

场景:操场排队,例如一行同学站队,要求各自比较一下身边的同学的身高,比较左右两侧同学的身高,比自己高的站在自己的右手边,比自己矮的站在自己左手边。
选择排序
顾名思义,每次选择一个最小(最大)的数值放在前面。

插入排序
想象场景:玩扑克牌时起牌的过程,小的牌插在前面,大的牌插在后面。
过程:在数列中任选一个数值(一般选择第一个)放在已排序数列里,然后遍历剩余数值,进行比较插入到已排序数列里。

快速排序
快速排序(Quicksort)是对冒泡排序的一种改进。
基本思想是:分治思想。从数列中挑出一个元素作为基准(pivot),通过一趟排序将要排序的数据分割成独立的两部分,比基准小的排在前面,比基准大的排在后面。然后再按递归地对这两部分数据分别进行快速排序。

计数排序
map排序好理解一些。
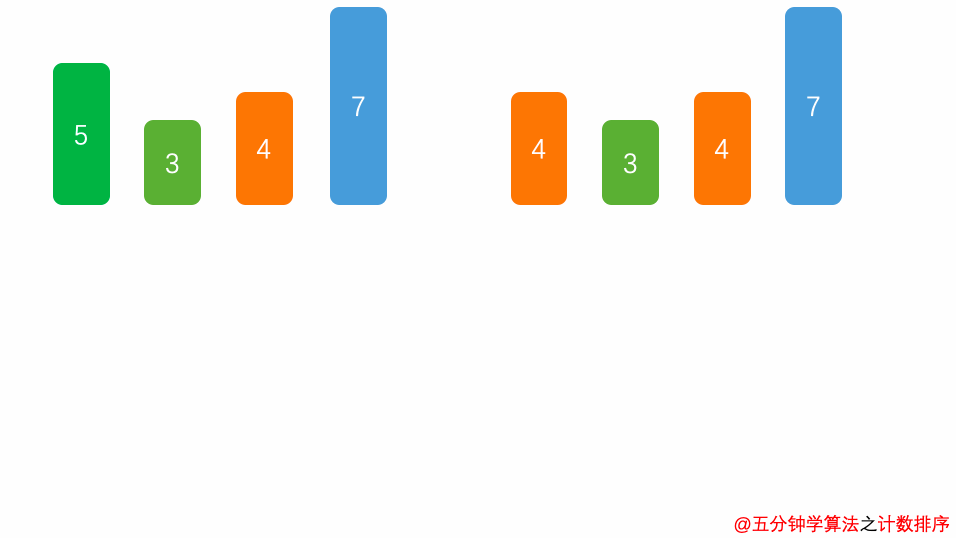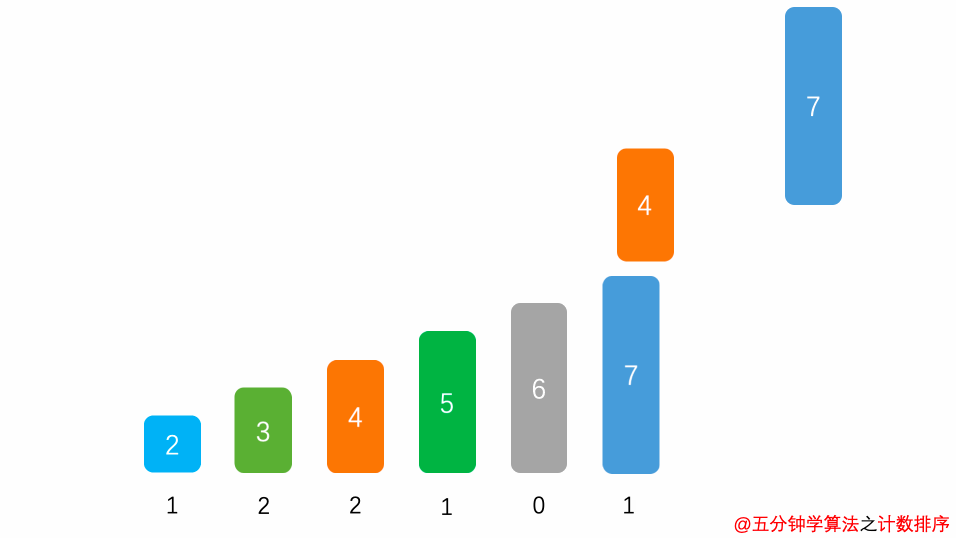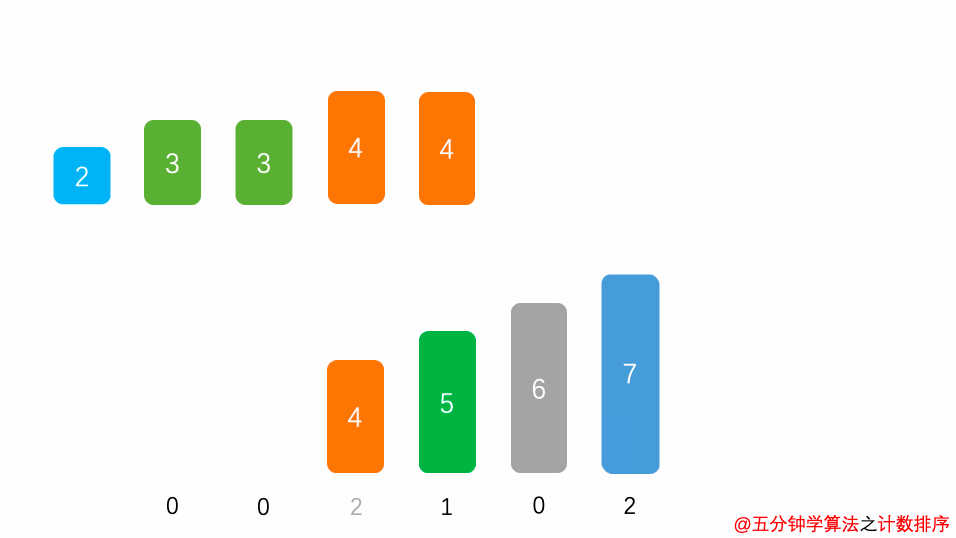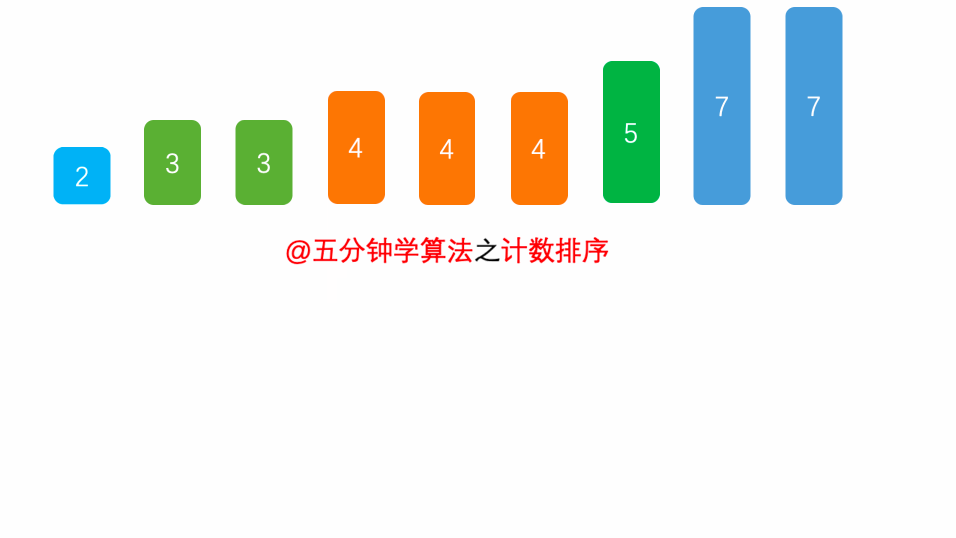
为什么称之为计数排序呢?因为来源于计数场景,统计以下字符串中每个字母的个数:
dlasdlfjaslksdjfjasllklj
for c in s:
arr[c] += 1
最简单也是最直观的想法就是建立一个数组Dict(),数组的第一个元素代表A,第二个元素代表B…第24个元素代表Z。然后就是遍历整个字符串,对每个字母都判断它对应着数组的哪个元素。比如遇到字母C,就执行Dict(3)+=1。
运行之后,数组的内容就是代表了每个字母出现的位置。比如Dict(2)是9,就代表字母B出现了9次,比如Dict(24)=0,代表字母Z从未出现过。
然后再出一个题目,把这些字母按照字母顺序排序,你会想到什么?冒泡排序,快速排序?
其实,上面统计字母出现次数的算法不就已经是给字母排序了吗?而且复杂度是O(n)的。
桶排序
桶排序是计数排序的扩展,计数排序可以看成是每个桶只存储相同数值的元素,而桶排序存储一定范围的元素。
通过映射函数,将待排序数组的元素映射到各个对应的桶中,再递归地对每个桶中的元素进行排序,最后将非空桶中的元素逐个放入有序序列中。
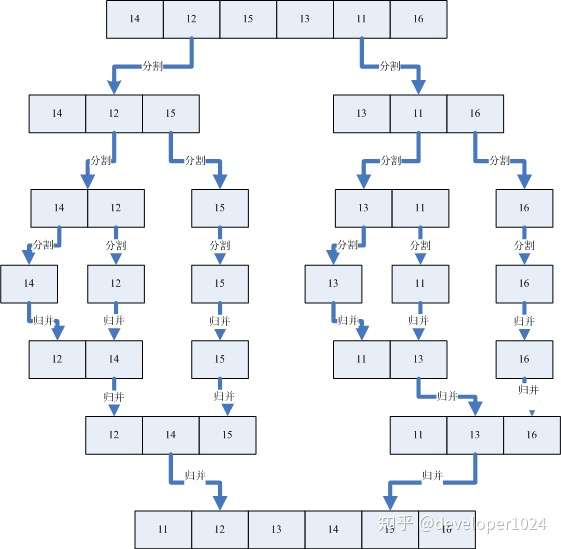
归并排序

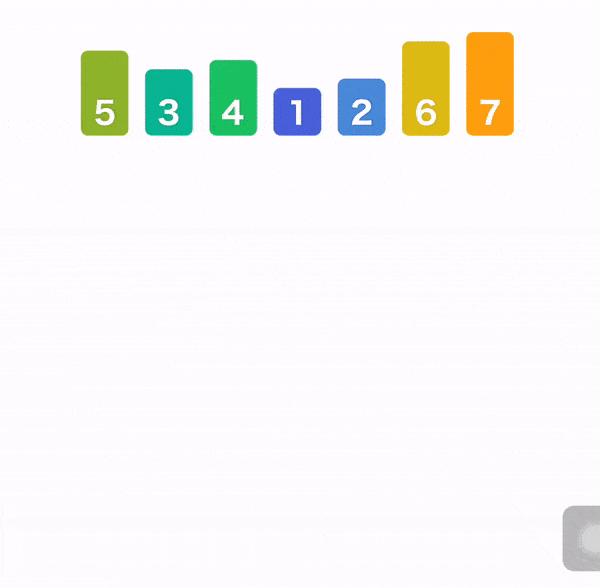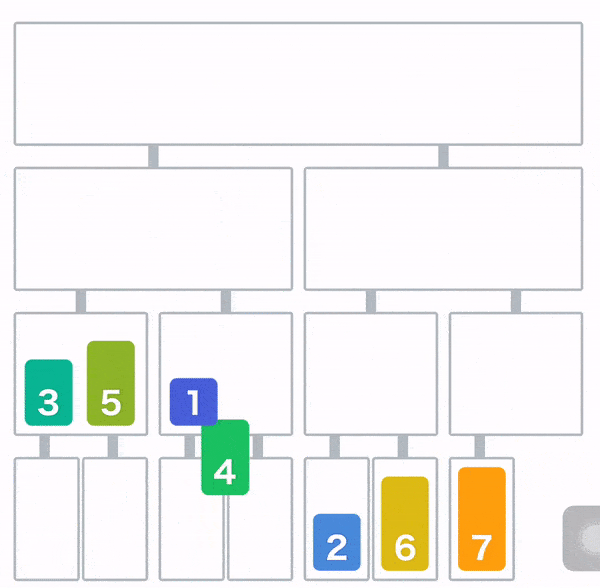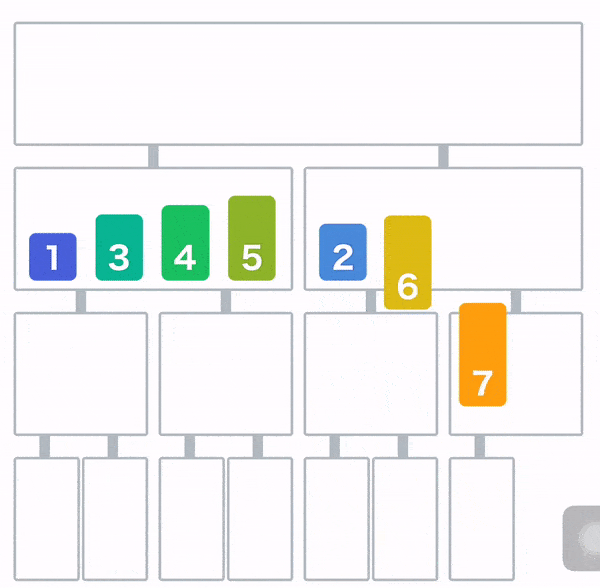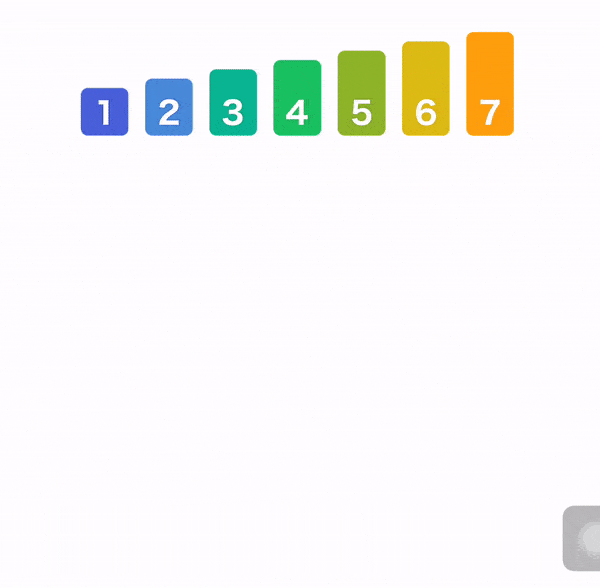
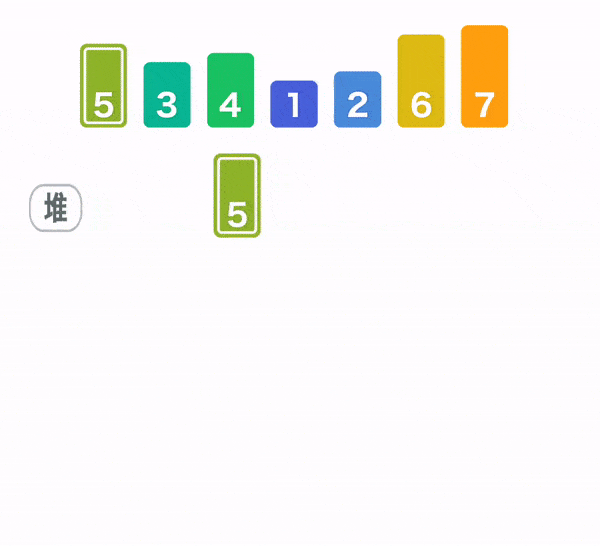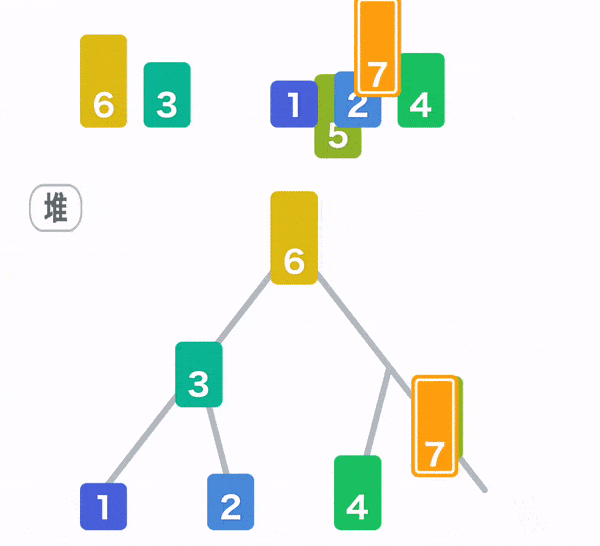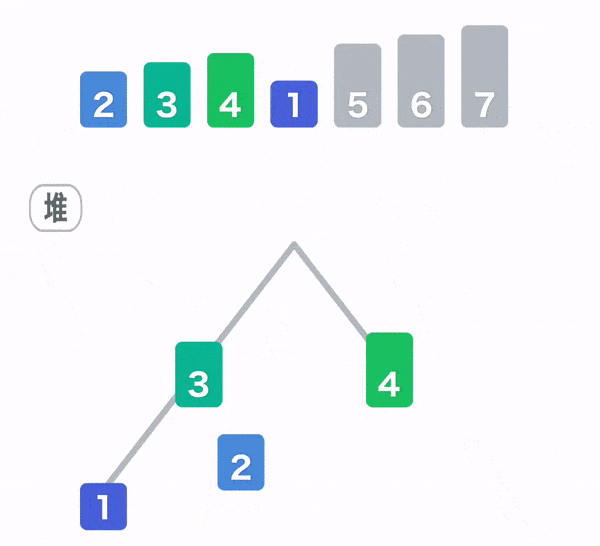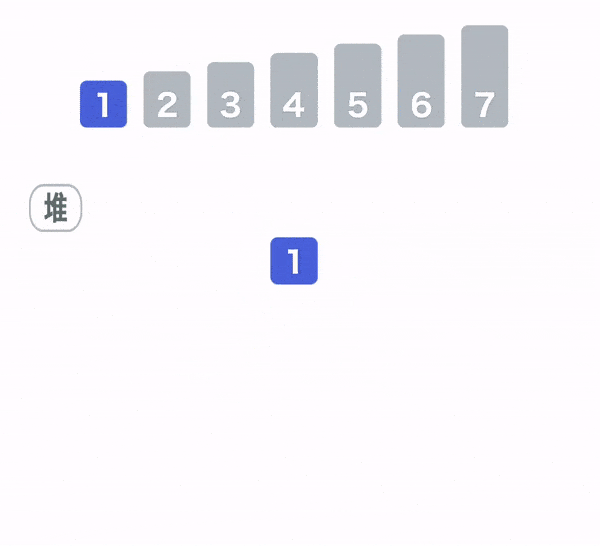
堆排序
文档信息
- 本文作者:zhupite
- 本文链接:https://zhupite.com/program/%E6%8E%92%E5%BA%8F%E7%AE%97%E6%B3%95%E6%B1%87%E6%80%BB.html
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)