同时兼容Python2和Python3的使用方式:
print()
异常
同时兼容Python2和Python3的使用方式:
try:
pass
except Exception as e:
pass
StringIO
from io import StringIO 或者import io 使用的时候:io.StringIO
unicode
这个没了,这个算是Python2比较麻烦的地方,特别是在Windows下开发经常需要转换:
# win下命令行参数为gbk编码:star.gbk2unicode(sys.argv[1]) + u'也有'
def gbk2unicode(s):
return s.decode('gbk', 'ignore')
# 脚本文件#coding:utf-8时默认不带u的字符串为utf8字符串:star.utf82unicode('我')
def utf82unicode(s):
return s.decode('utf-8', 'ignore')
# 带u的字符串为unicode
# star.unicode2gbk(u'\u4e5f\u6709')
# star.unicode2gbk(u'也有')
def unicode2gbk(s):
return s.encode('gbk')
# 带u的字符串为unicode
# star.unicode2utf8(u'\u4e5f\u6709')
# star.unicode2utf8(u'也有')
def unicode2utf8(s):
return s.encode('utf-8')
# win下命令行参数为gbk编码:star.gbk2utf8(sys.argv[1]) + '也有'
def gbk2utf8(s):
return s.decode('gbk', 'ignore').encode('utf-8')
def utf82gbk(s):
return s.decode('utf-8', 'ignore').encode('gbk')
但是在Python3下面不需要了。
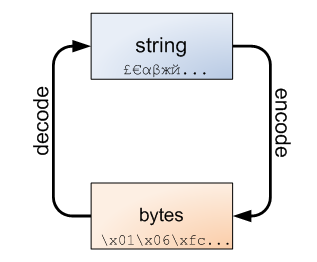
str与bytes
python3最重要的新特性也是对文本和二进制数据做了更清晰的区分。虽然没了unicode的转换,但是多了str与bytes的转换,如果出现下面异常:
a bytes-like object is required, not 'str'
你需要将字符串转换为字节:
bytes(str, 'UTF-8')
如果出现下面异常:
must be str, not bytes
你需要将字节转换为字符串:
str(t.read(),"utf-8")
python有两种类型转换的函数encode(),decode() 。
encode(编码),可以将str类型编码为bytes。
decode(译码),可以将bytes类型转换为str类型。
引用py文件(import)
同目录下的py文件引用,使用.(点)。
- 引用同目录下的py文件中的某个类:from .AXMLPrinter import AXMLPrinter
- 应用同目录下的py文件中的所有:from . import Constant
文档信息
- 本文作者:zhupite
- 本文链接:https://zhupite.com/python/python3.html
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)